未來之窗 歐美科技類網(wǎng)站首頁設計理念與實踐
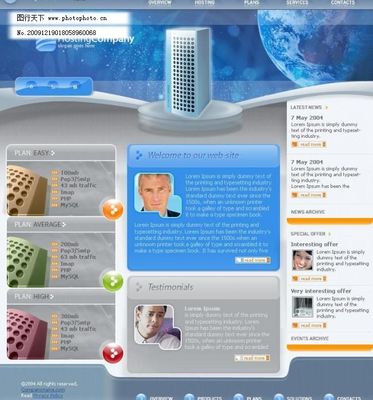
在當今數(shù)字化浪潮中,科技類網(wǎng)站不僅是信息展示的窗口,更是品牌形象、用戶體驗與前沿技術(shù)的交匯點。歐美科技類網(wǎng)頁模板,尤其是首頁(Home)設計,以其簡潔、現(xiàn)代、高效和高度互動的特點,引領著全球網(wǎng)頁設計的風向。本文將深入探討其核心設計理念、關(guān)鍵元素以及制作實踐,為打造出色的科技類網(wǎng)站首頁提供清晰指引。
一、 核心設計理念:簡約、清晰與用戶為中心
歐美科技類首頁設計的精髓在于“少即是多”。頁面布局力求干凈、開闊,避免信息過載。設計通常遵循以下原則:
- 極簡主義與留白藝術(shù):大量運用留白(Negative Space)來突出核心內(nèi)容,如產(chǎn)品展示、價值主張或最新動態(tài),營造出高端、專業(yè)的視覺感受。
- 清晰的信息層級:通過字體大小、粗細、顏色和區(qū)塊劃分,建立明確的信息閱讀順序。用戶視線應能自然地從品牌標識、核心標語,流向關(guān)鍵功能或產(chǎn)品介紹,最后至詳細信息或行動號召。
- 以用戶旅程為導向:設計始終圍繞用戶的目標展開。首頁的每一個模塊——從導航欄到頁腳——都旨在快速解答用戶疑問:“這是什么?”、“能為我做什么?”、“我該如何開始?”。
二、 關(guān)鍵視覺與交互元素
一個典型的歐美科技首頁模板通常包含以下模塊:
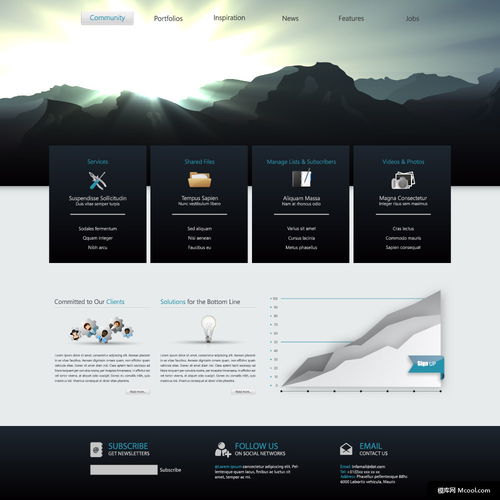
- 導航欄(Navigation Bar):固定在頁面頂部,簡潔明了。通常包含Logo、核心產(chǎn)品/服務鏈接(如“解決方案”、“產(chǎn)品”、“定價”)、資源中心(博客、文檔)和明顯的“登錄/注冊”或“免費試用”按鈕。
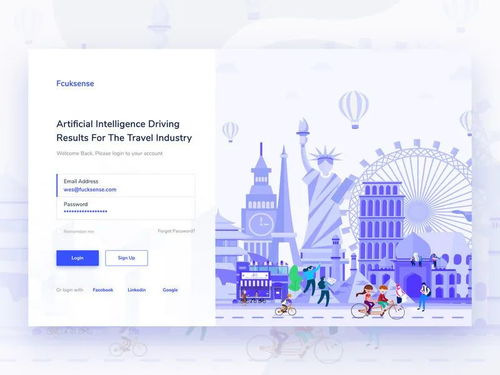
- 英雄區(qū)域(Hero Section):首屏核心,用于制造第一印象。通常包含一個強有力的主標題、一句精煉的副標題、一張富有科技感的背景圖或動態(tài)視頻,以及一個突出的主要行動號召按鈕(如“立即開始”、“觀看演示”)。
- 價值主張展示:緊接著英雄區(qū)域,通過圖標、簡短標題和描述,以三到四個區(qū)塊清晰展示公司或產(chǎn)品的核心優(yōu)勢與功能。
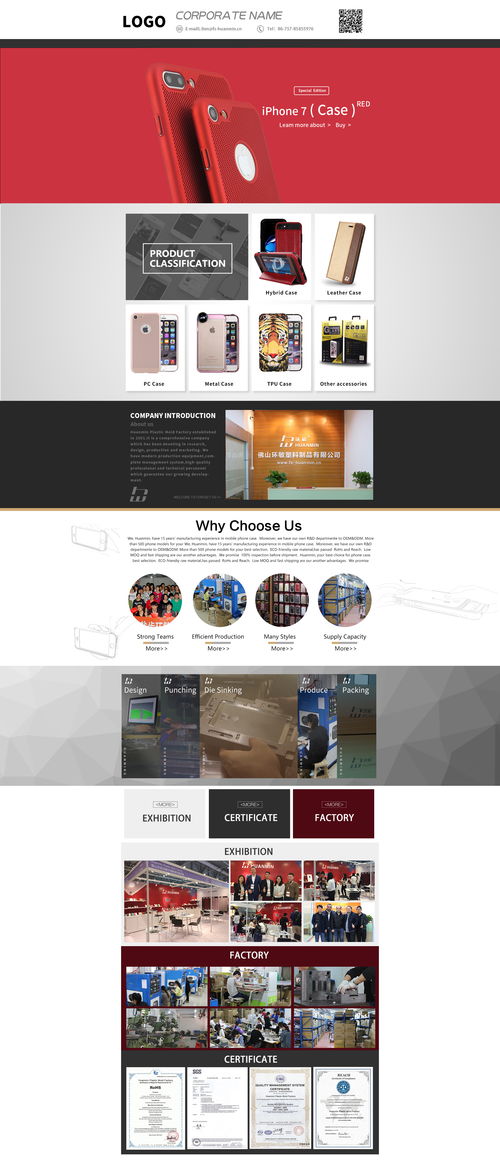
- 產(chǎn)品/服務亮點:使用高質(zhì)量的圖片、截圖、交互式演示或短視頻,直觀展示產(chǎn)品界面、工作流程或技術(shù)原理。常伴隨簡潔的文字說明。
- 社會證明(Social Proof):集成知名客戶Logo、用戶評價、案例研究或媒體報道,快速建立信任感。
- 最新動態(tài)與博客摘要:展示公司新聞、行業(yè)見解或最新技術(shù)文章,體現(xiàn)思想領導力和品牌活力,同時有助于SEO。
- 最終行動號召(Final CTA):在頁面底部再次放置一個明確的行動號召,如“聯(lián)系我們”、“申請演示”或“開始免費試用”,轉(zhuǎn)化猶豫不決的用戶。
- 頁腳(Footer):結(jié)構(gòu)清晰,包含版權(quán)信息、重要鏈接(隱私政策、服務條款)、社交媒體圖標和可能的聯(lián)系方式或簡化的導航。
三、 技術(shù)實現(xiàn)與制作要點
在具體制作時,需關(guān)注以下幾點:
- 響應式設計(Responsive Design):確保網(wǎng)站在桌面、平板、手機等各種設備上都能完美呈現(xiàn)和操作。使用CSS媒體查詢和彈性布局(如Flexbox, Grid)。
- 性能優(yōu)化:科技用戶對速度極為敏感。需優(yōu)化圖片(使用WebP格式、懶加載)、壓縮代碼、利用瀏覽器緩存,并考慮使用內(nèi)容分發(fā)網(wǎng)絡(CDN)。
- 現(xiàn)代前端技術(shù)棧:可以采用流行的框架和庫,如React, Vue.js 或 Angular 來構(gòu)建動態(tài)、組件化的界面。搭配Sass/Less等CSS預處理器管理樣式。
- 微交互與動畫:謹慎使用平滑滾動、懸停效果、漸入動畫等微交互,能提升用戶體驗的精致感和現(xiàn)代感,但切忌過度使用影響性能或分散注意力。
- 可訪問性(Accessibility):確保網(wǎng)站對所有用戶友好,包括殘障人士。合理使用ARIA標簽、確保足夠的顏色對比度、支持鍵盤導航等。
四、 設計工具與資源
設計師常用Figma, Sketch, Adobe XD進行高保真原型設計。開發(fā)者則可在CodePen, GitHub上找到大量開源模板和組件庫(如Tailwind CSS組件、Bootstrap主題)作為起點,加速開發(fā)進程。
一個成功的歐美風格科技首頁,是理性邏輯與感性美學的結(jié)合。它需要精準傳達復雜的技術(shù)概念,同時提供流暢、直觀且令人愉悅的瀏覽體驗。通過貫徹簡約清晰的設計哲學,聚焦核心價值,并善用現(xiàn)代Web技術(shù),任何團隊都能打造出專業(yè)、可信且具有吸引力的科技門戶,在數(shù)字世界中脫穎而出。
如若轉(zhuǎn)載,請注明出處:http://www.fuhp.cn/product/54.html
更新時間:2026-04-12 02:51:13